空间查询
- 最邻近查询:给定一个点或者对象,查询满足条件的最近对象
- 区域查询:查询全部或者部分落在限定区域内的对象

空间索引结构
基于空间分割的索引结构
- Grid-based
Quad-tree
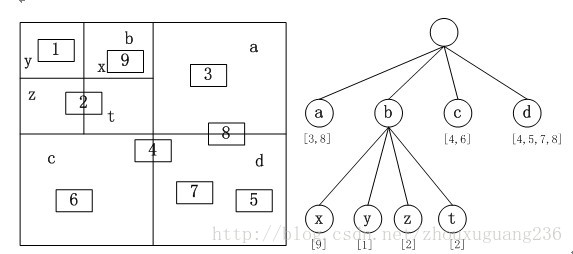
四叉树索引的基本思想是将地理空间递归划分为不同层次的树结构。它将已知范围的空间等分成四个相等的子空间,如此递归下去,直至树的层次达到一定深度或者满足某种要求后停止分割。四叉树的结构比较简单,并且当空间数据对象分布比较均匀时,具有比较高的空间数据插入和查询效率,因此四叉树是GIS中常用的空间索引之一。常规四叉树的结构如图所示,地理空间对象都存储在叶子节点上,中间节点以及根节点不存储地理空间对象。
四叉树对于区域查询,效率比较高。但如果空间对象分布不均匀,随着地理空间对象的不断插入,四叉树的层次会不断地加深,将形成一棵严重不平衡的四叉树,那么每次查询的深度将大大的增多,从而导致查询效率的急剧下降。四叉树结构是自顶向下逐步划分的一种树状的层次结构。传统的四叉树索引存在着以下几个缺点:
- 空间实体只能存储在叶子节点中,中间节点以及根节点不能存储空间实体信息,随着空间对象的不断插入,最终会导致四叉树树的层次比较深,在进行空间数据窗口查询的时候效率会比较低下。
- 同一个地理实体在四叉树的分裂过程中极有可能存储在多个节点中,这样就导致了索引存储空间的浪费。
- 由于地理空间对象可能分布不均衡,这样会导致常规四叉树生成一棵极为不平衡的树,这样也会造成树结构的不平衡以及存储空间的浪费。
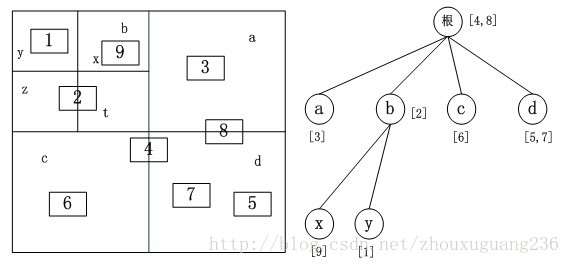
相应的改进方法,将地理实体信息存储在完全包含它的最小矩形节点中,不存储在它的父节点中,每个地理实体只在树中存储一次,避免存储空间的浪费。首先生成满四叉树,避免在地理实体插入时需要重新分配内存,加快插入的速度,最后将空的节点所占内存空间释放掉。改进后的四叉树结构如下图所示。四叉树的深度一般取经验值4-7之间为最佳。
- k-D tree
数据驱动的索引结构
R-Tree
R树很好的解决了高维空间搜索问题。它把B树的思想扩展到多维空间,采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解结点的方法,保证树的平衡性。因此,R树就是一棵用来存储高维数据的平衡树。
R树的数据结构
R树是B树在高维空间的扩展,是一棵平衡树。每个R树的叶子结点包含了多个指向不同数据的指针,这些数据可以是存放在硬盘中的,也可以是存在内存中。根据R树的这种数据结构,当我们需要进行一个高维空间查询时,我们只需要遍历少数几个叶子结点所包含的指针,查看这些指针指向的数据是否满足要求即可。这种方式使我们不必遍历所有数据即可获得答案,效率显著提高。下图1是R树的一个简单实例:
R树采用了一种称为MBR(最小边界矩形,Minimal Bounding Rectangle)的方法进行空间分割。从叶子结点开始用矩形(rectangle)将空间框起来,结点越往上,框住的空间就越大,以此对空间进行分割。我们就拿二维空间来举例。下图是Guttman论文中的一幅图:
- 首先我们假设所有数据都是二维空间下的点,图中仅仅标志了R8区域中的数据,也就是那个shape of data object。别把那一块不规则图形看成一个数据,我们把它看作是多个数据围成的一个区域。为了实现R树结构,我们用一个最小边界矩形恰好框住这个不规则区域,这样,我们就构造出了一个区域:R8。R8的特点很明显,就是正正好好框住所有在此区域中的数据。其他实线包围住的区域,如R9,R10,R12等都是同样的道理。这样一来,我们一共得到了12个最最基本的最小矩形。这些矩形都将被存储在子结点中。
- 下一步操作就是进行高一层次的处理。我们发现R8,R9,R10三个矩形距离最为靠近,因此就可以用一个更大的矩形R3恰好框住这3个矩形。
- 同样道理,R15,R16被R6恰好框住,R11,R12被R4恰好框住,等等。所有最基本的最小边界矩形被框入更大的矩形中之后,再次迭代,用更大的框去框住这些矩形。
我想大家都应该理解这个数据结构的特征了。用地图的例子来解释,就是所有的数据都是餐厅所对应的地点,先把相邻的餐厅划分到同一块区域,划分好所有餐厅之后,再把邻近的区域划分到更大的区域,划分完毕后再次进行更高层次的划分,直到划分到只剩下两个最大的区域为止。要查找的时候就方便了。
下面就可以把这些大大小小的矩形存入我们的R树中去了。根结点存放的是两个最大的矩形,这两个最大的矩形框住了所有的剩余的矩形,当然也就框住了所有的数据。下一层的结点存放了次大的矩形,这些矩形缩小了范围。每个叶子结点都是存放的最小的矩形,这些矩形中可能包含有n个数据。

GeoSpark
SpatialSpark
SpatialSpark和SparkDistributedMatrix调研小结
Spatial Database
城市计算
轨迹数据挖掘